
캐시란?
캐시란, 데이터 접근속도를 높이기 위해 원본 데이터를 복사하여 미리 저장해두는것을 의미한다.
메모리 Hireachy에 따라, 상단으로 올라갈수록 접근 속도가 높은 대신 저장공간이 작으며, 하단으로 내려갈수록 속도가 낮은 대신 저장공간이 크다. 원본 데이터는 일반적으로 보조 기억 장치 레벨에 저장되며, 이에따라 접근 속도는 현저히 떨어진다.

캐시는 보조 기억 장치에 저장되는 데이터들을 메모리 레벨에 미리 저장해둠으로써 응답속도를 비약적으로 개선한다.
하지만, 다음과 같은 세가지 쟁점이 뒤따른다.
캐시 저장 데이터
캐싱을 사용함으로써 빠른 접근속도를 가지는 대신, 작은 저장공간을 가진다.
따라서, 어떤 데이터를, 얼마나, 어떻게 저장할지 고민해야한다.
데이터 불일치
원본 데이터를 복사하여 저장됨에 따라, 캐시에 저장된 데이터가 원본 데이터와 다를 수 있다. (정합성문제)
장애 발생지점 ( 선택적 )
레디스와 같은 추가적인 인프라를 도입할 시 장애 발생이 가능하다.
이 세가지 쟁점에 집중하여 캐시전략들을 살펴볼 것이다.
각 캐시전략에 따라 네트워크 접근 빈도가 달라질 수 있으며 성능에 영향을 끼칠 수 있다.
하지만 이는 Storage레벨 접근에 비하면 아주 미미한 수준임으로 최적화 후순위로 미루는것이 옳다.
캐시 쓰기 전략
클라이언트가 쓰기작업을 요청할때, 캐시 - 오리진에 데이터를 어떻게 저장할지에 대한 전략이다.
Client는 클라이언트 코드를 의미하며
Origin은 원본 데이터가 저장된 곳을 의미한다.
Write Around
쓰기작업 시, 데이터는 항상 Origin에만 작성하도록 한다. 캐시엔 접근하지 않는다.
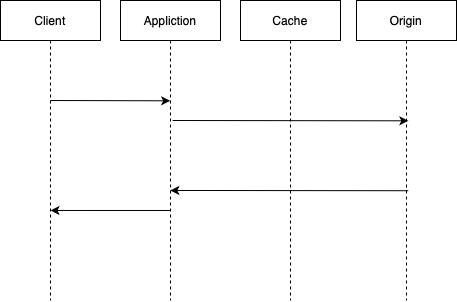
캐시 저장 데이터
- 데이터를 적재 하지 않는다. 캐시 메모리 공간을 사용하지 않는다.
데이터 불일치
- 캐시에 적재된 데이터와 오리진 데이터가 불일치 할 수 있다.
장애 발생지점
- 항상 Origin에 데이터를 작성함으로 캐시장애에 의한 영향이 없다.
1. 쓰기 요청이 빈번하지 않은 데이터 + 쓰기만 하고 읽지 않는 데이터
2. 쓰기 요청이 빈번하지 않은 데이터 + 실시간 정합성이 중요하지 않은 데이터 ( 약간의 불일치 허용 )
캐시를 쓰는 것 또한 비용이기 때문에, 캐시를 안쓰는것도 하나의 전략이다.
해당 데이터를 캐시에 적재하지 않음으로써, 다른 데이터들의 캐시적재 유도
Write Through
캐시에 데이터를 적재하며, 동기적으로 데이터를 오리진에 반영한다. 이에따라 클라이언트 응답속도는 더 느리다.

캐시 저장 데이터
- 쓰기요청 데이터가 모두 저장된다. 이에따라 저장공간 사용량이 크다.
- 캐시에 오리진 스키마와 독립적인 모델로 저장가능하다.
데이터 불일치
- 캐시와 Origin은 항상 같은 데이터를 유지한다.
장애 발생지점
- 캐시 장애 발생, 서비스가 중단된다.
1. 쓰기요청이 빈번하지 않은 데이터 + 쓰자마자 많은 읽기 요청이 예상되는 데이터 + 유실 방지
Write Back
캐시에만 데이터를 적재하고 비동기적으로 오리진에 반영한다. 클라이언트 응답속도가 가장 빠르다

캐시 저장 데이터
- 쓰기 데이터가 모두 저장된다. 이에따라 저장공간 사용량이 크다.
- 캐시에 독립적인 모델로 저장가능하다.
데이터 불일치
- 캐시와 Origin 은 최종적으로 같은 데이터를 유지한다. ( 최종적 일관성 )
장애 발생지점
- 캐시 장애 발생시 오리진에 데이터가 유실될 수 있다.
- 캐시 장애 발생시 서비스가 중단된다.
1. 쓰기요청이 빈번한 데이터 + 쓰자마자 읽기 요청이 예상되는 데이터 + 유실 허용
실시간 응답 + 정합성
캐시 읽기 전략
캐시를 읽는 두가지 전략이다.
둘의 주요 차이점은 장애전파와, 데이터 모델링 두 부분이다.
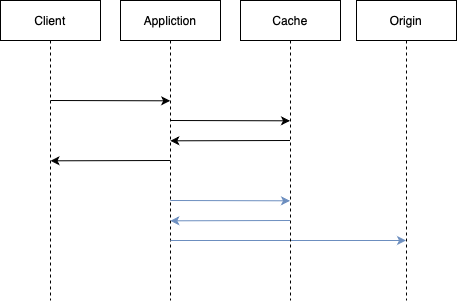
Cache Aside (Look Aside)
클라이언트의 읽기 작업 시, 캐시를 먼저 조회한다.
캐시미스 시, Origin을 조회하여 데이터를 캐시에 적재한다.


캐시 저장 데이터
- 읽는 데이터를 캐시에 적재한다.
- 캐시에 저장될 데이터 형식은 클라이언트 주도로 설계될 수 있다.
캐시 데이터 불일치
- 캐시 미스 발생 이전까지 데이터 불일치.
장애 발생지점 증가
- 캐시 장애 발생시, 서비스는 계속 지속된다.
- 하지만, 응답속도는 현저히 느려지며, 오리진으로 장애전파가 이뤄질 수 있다.
Read Through
클라이언트의 읽기 작업 시, 캐시만 조회한다.
캐시 적재 과정은 캐시와 오리진 사이에서만 일어난다.

캐시 저장 데이터
- 읽는 데이터를 캐시에 적재한다.
- 캐시에 저장될 데이터는 Origin에 의존한다.
캐시 데이터 불일치
- 캐시 미스 발생 이전까지 데이터 불일치.
장애 발생지점 증가
- 캐시 장애 발생시, 서비스가 중단된다.
- 하지만 동시에, 오리진으로의 장애전파를 막을 수 있다.
'Spring' 카테고리의 다른 글
| Embedded Tomcat - NIO (0) | 2025.04.08 |
|---|